How tall the VIBASS’ participants are?
One of the most commonly used examples of Normal data are heights and weights. We want to continue this tradition. We will dedicate this practice to work with the heights of the VIBASS participants of the past editions. We start first with the height of the women.

Some VIBASS’ participants.
Bayesian inference for the mean height of the women VIBASS’ participants. The variance of the sampling Normal model is known.
The data
We have the following height data, in metres, for a random sample of women participants from previous editions of VIBASS.
hwomen <- data.frame(height = c(1.73, 1.65, 1.65, 1.76, 1.65, 1.63, 1.70, 1.58, 1.57, 1.65, 1.74, 1.68, 1.67, 1.58, 1.66))We can summarize the data and represent them by means of a histogram.
summary_table(
mean = mean(hwomen$height),
var = var(hwomen$height),
quant = quantile(hwomen$height, probs = c(0, 0.25, 0.5, 0.75, 1)),
label = "Women height",
digits = 3
)| Summary | Women height |
|---|---|
| Mean | 1.660 |
| Var | 0.003 |
| S.Dev | 0.057 |
| Min. | 1.570 |
| Q25 | 1.640 |
| Q50 | 1.650 |
| Q75 | 1.690 |
| Max. | 1.760 |
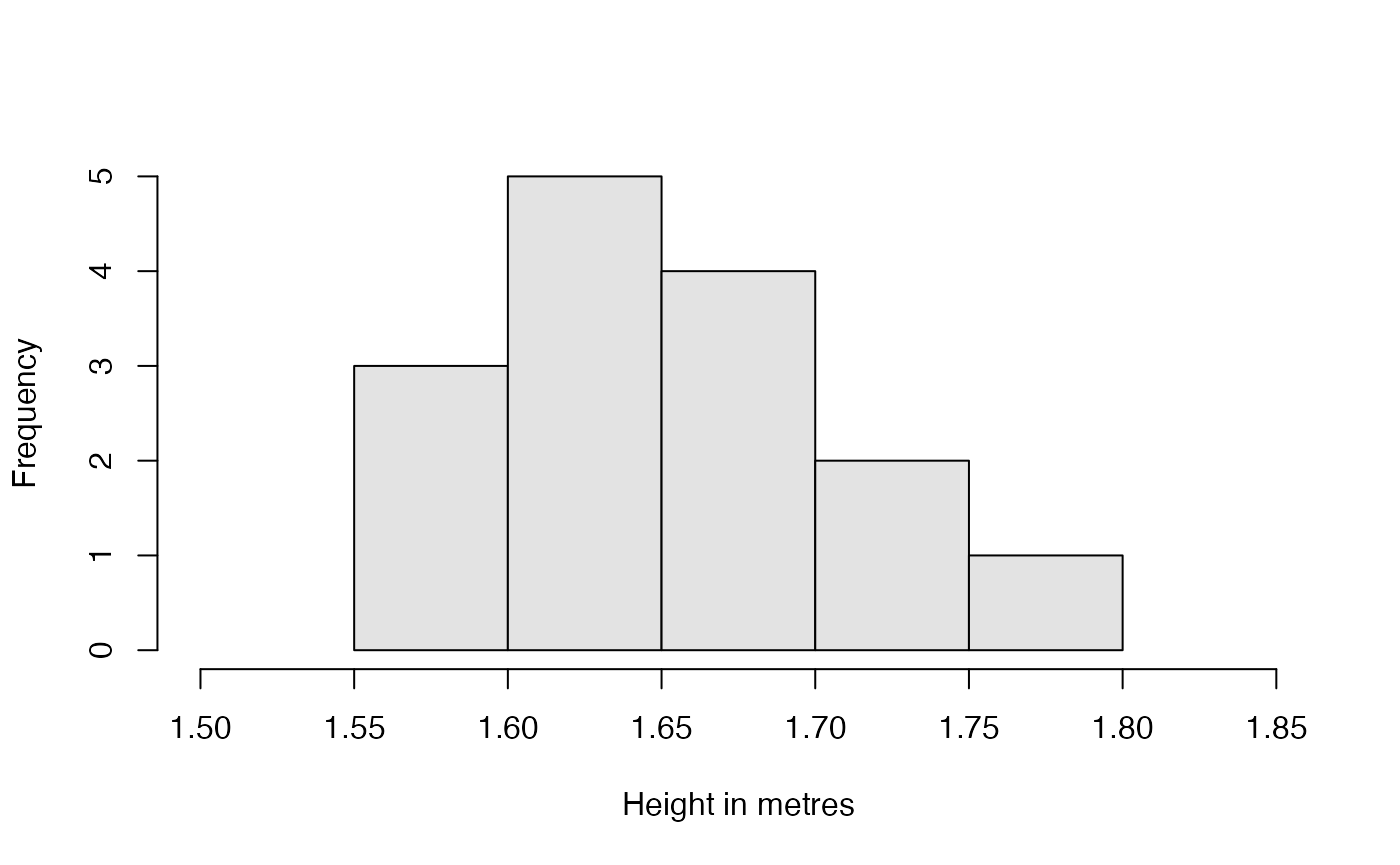
The histogram obtained does not remind us much of the Normal distribution. But we know that when we work with small amounts of data, even if they are Normal, we cannot expect their histogram to look like a symmetrical bell. In fact, if we were to generate small Normal data samples, few of them would resemble the Gaussian ideal.
The sampling model is approximately Normal
Let be the random variable that describes the height of the women in VIBASS. We assume that given the mean of the height of the VIBASS women , the distribution of is Normal with mean and standard deviation .
whose conditional density function, expectation and variance are:
- ,
A prior distribution for
Recall that the Normal distribution is conjugate with respect to the Normal probability model with known. If we elicit a Normal prior distribution for , its density is
with prior mean and and variance
- ,
We are going to work with a prior distribution based on the information from two of the VIBASS lecturers. This prior distribution is
On the basis of this distribution these two teachers think that the mean of the height of women VIBASS participants is centred on m with a standard deviation of m. According to it, we can compute the following percentile and probabilities
qnorm(c(0.005, 0.995), 1.70, 0.07)
#> [1] 1.519692 1.880308
pnorm(c(1.50, 1.60, 1.70, 1.80, 1.90), 1.70, 0.07)
#> [1] 0.002137367 0.076563726 0.500000000 0.923436274 0.997862633Consequently, a 99 credible interval for is which means that the probability that a VIBASS participant is neither taller than 1.88 metres nor shorter than 1.52 is 0.99. The probability that she is shorter than 1.50 is 0.0021, the probability that her height is between 1.60 and 1.80 is 0.9234-0.0766= 0.8468 or the probability that is taller than 1.80 is 1-0.9234=0.0766. Next we show the graphic of the density of this prior distribution.
cap <- "Prior distribution for the mean height."
m0 <- 1.7; s0 <- 0.07
curve(
dnorm(x, m0, s0),
xlab = expression(paste(mu)), ylab = "prior",
xlim = c(1.40, 2), lwd = 4, col = "dodgerblue", yaxt = "n"
)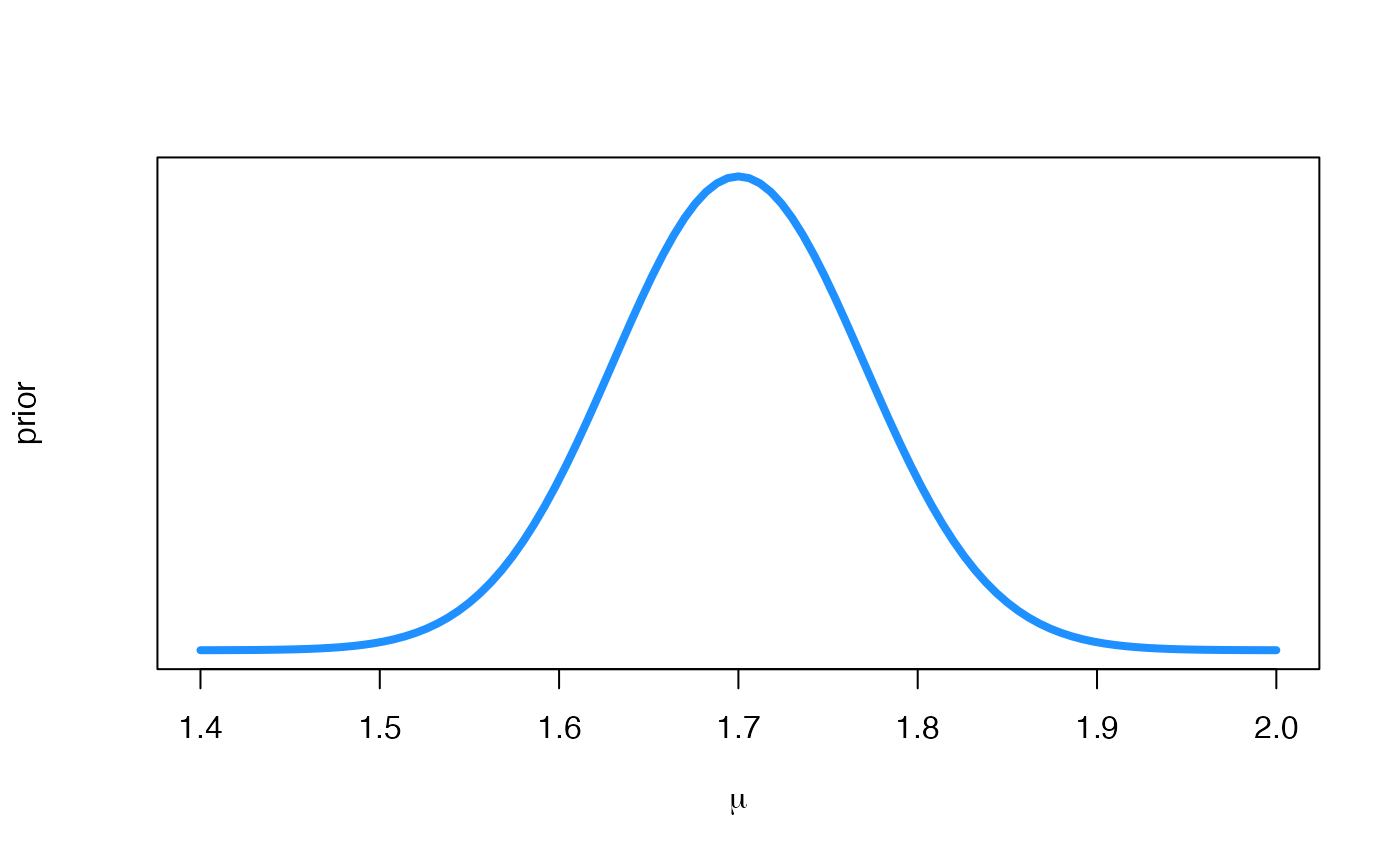
Prior distribution for the mean height.
The likelihood function of
The likelihood is a function of for the data . It is defined as follows
where is the joint density of the ’s given evaluated in . Since the ’s are conditionally independent given , the joint density is the product of the marginal densities. In our case, the likelihood function of is
cap <- "Likelihood function."
Lnorm <- function(mu, y, sigma) {
# Essentially:
# prod(dnorm(y, mean = mu, sd = sigma))
# but we make it numerically more stable working on the log scale
# and we vectorise over mu
vapply(
mu,
function(.) exp(sum(dnorm(y, mean = ., sd = sigma, log = TRUE))),
1
)
}
curve(
Lnorm(x, hwomen$height, 0.1),
xlab = expression(paste(mu)), ylab = "likelihood",
xlim = c(1.4, 2), col = "darkorange", lwd = 4, yaxt = "n"
)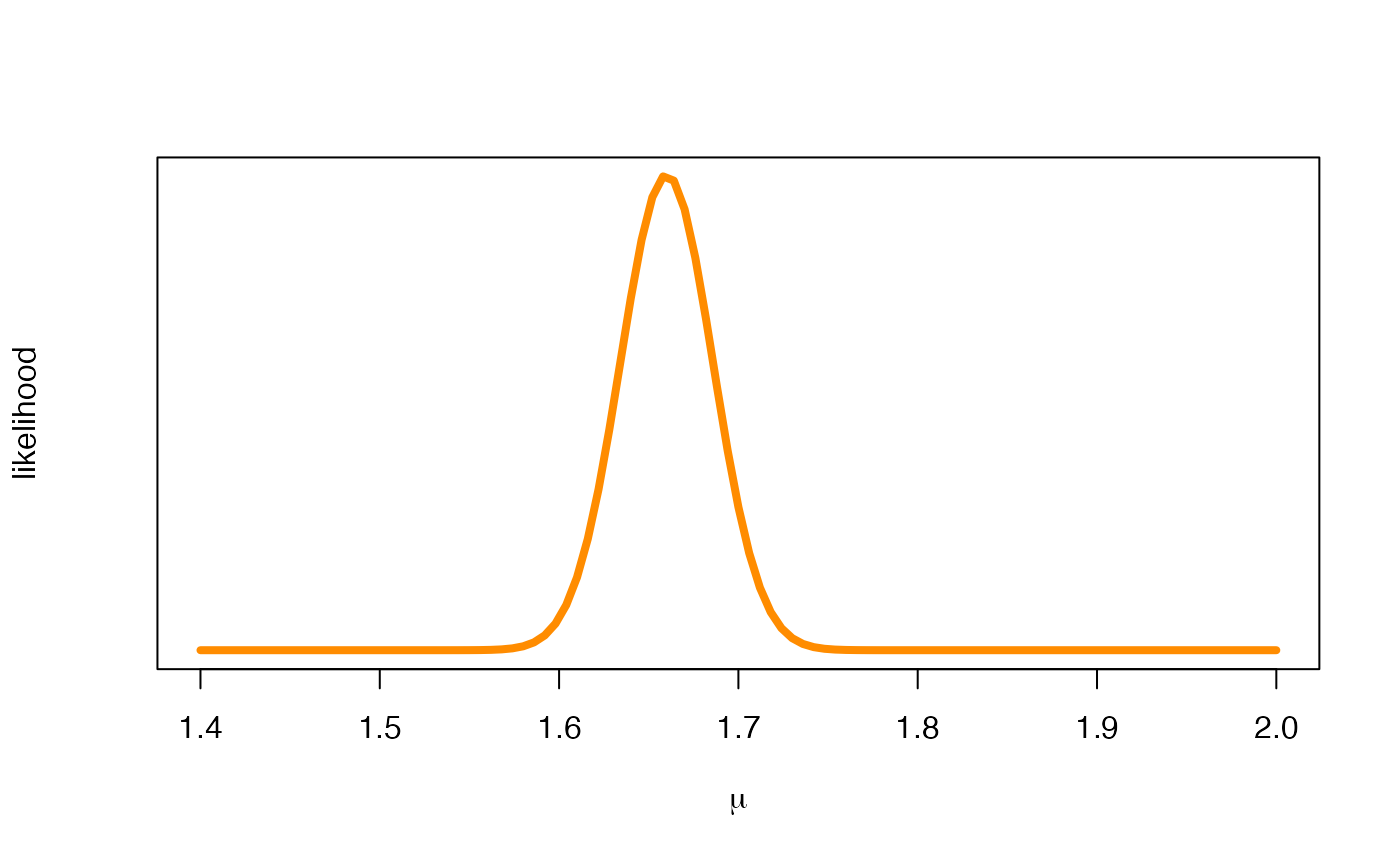
Likelihood function.
The posterior distribution of
The posterior distribution of is a Normal distribution with parameters
Next, we plot on the same graph the prior (in blue) and the posterior distribution (in green) of
m0 <- 1.7; s0 <- 0.07
m1 <- 1.6648; s1 <- 0.0242
curve(
dnorm(x, m1, s1),
xlab = expression(paste(mu)), ylab = "density",
xlim = c(1.40, 2), lwd = 4, col = "darkgreen", yaxt = "n"
)
curve(
dnorm(x, m0, s0),
lwd = 4, col = "dodgerblue", add = TRUE
)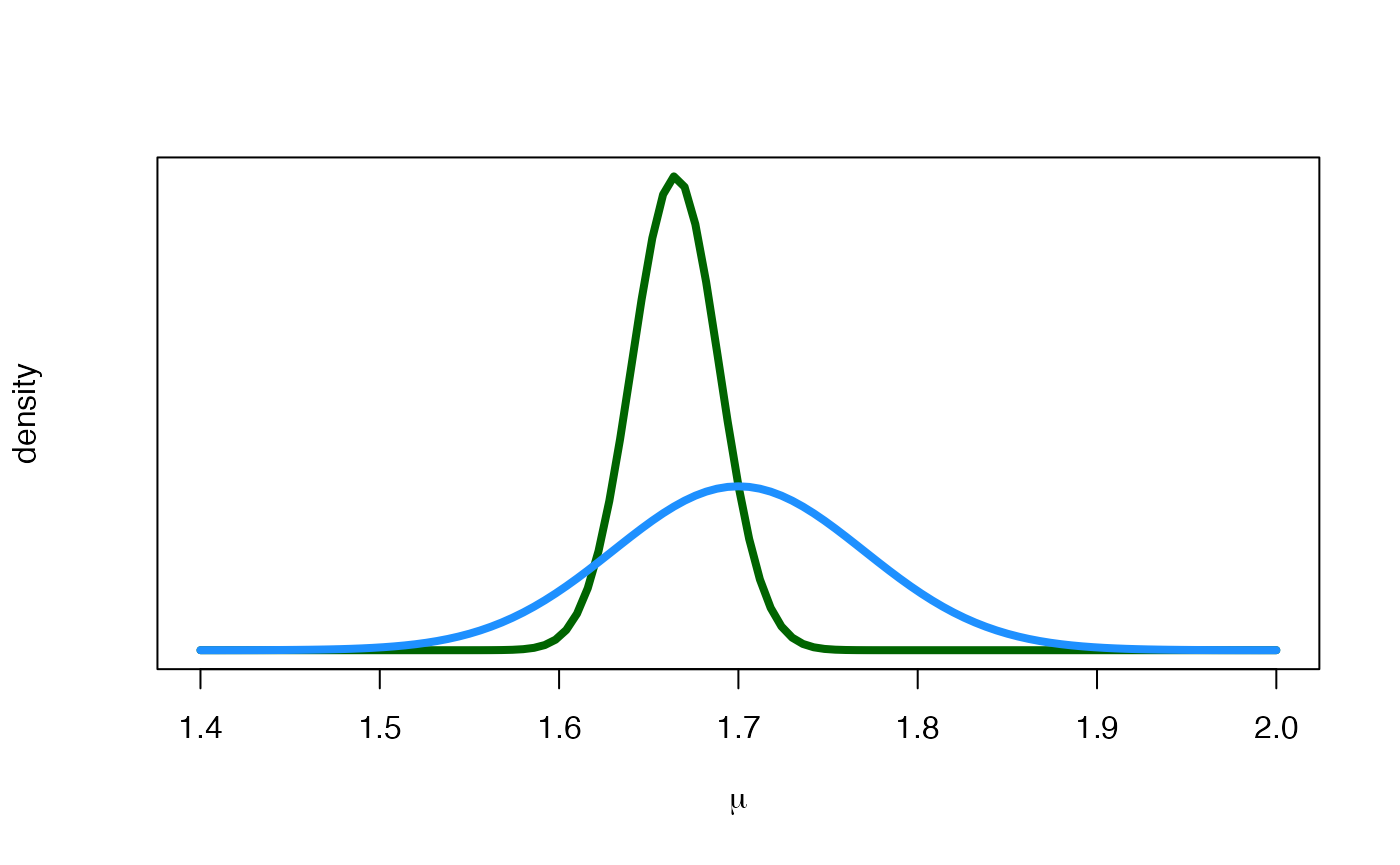
Prior (blue) and posterior (green) distributions for the mean height.
The visual difference between the two distributions is very clear: The posterior distribution has a very low variability compared to the prior ( m vs. m) and is slightly shifted to the left because the posterior mean is slightly lower than the prior mean ( vs. ).
On the basis of the posterior distribution, the two teachers now think that the mean of the height of women VIBASS participants is centred on with a standard deviation of metres. According to it, we can compute the following percentiles and probabilities
qnorm(c(0.005, 0.995), m1, s1)
#> [1] 1.602465 1.727135
pnorm(c(1.50, 1.60, 1.70, 1.80, 1.90), m1, s1)
#> [1] 4.882741e-12 3.706635e-03 9.271024e-01 1.000000e+00 1.000000e+00Consequently, a 99% credible interval for is , which means that the probability that a VIBASS participant is between 1.6 m and 1.73 m is 0.99. The probability that she is shorter than 1.50 m is , the probability that her height is between 1.60 m and 1.80 m is or the probability that is taller than 1.80 m is 0.0000.
The posterior predictive distribution for the height of a new VIBASS participant
We are interested in predicting the height of Aninè, a new female VIBASS participant who has not participated in the sample of the inferential process. In this case, the posterior predictive distribution for the Aninè’s height is a Normal distribution
with standard deviation .
It is important to note that the mean of this predictive distribution coincides with the mean of the posterior distribution of . However, the enormous variability of the predictive distribution, which depends on the variability of the sampling model and the variability of the a posteriori distribution, is very striking. The following figure shows the posterior distribution (in green) of and the posterior predictive distribution (in purple) for Aninè’s height illustrating the previous comments.
mp <- m1; sp <- sqrt(s1^2 + 0.1^2)
curve(
dnorm(x, m1, s1),
xlab = expression(paste(mu)), ylab = "density",
xlim = c(1.40, 2), lwd = 4, col = "darkgreen", yaxt = "n"
)
curve(
dnorm(x, mp, sp),
lwd = 4, col = "purple", add = TRUE
)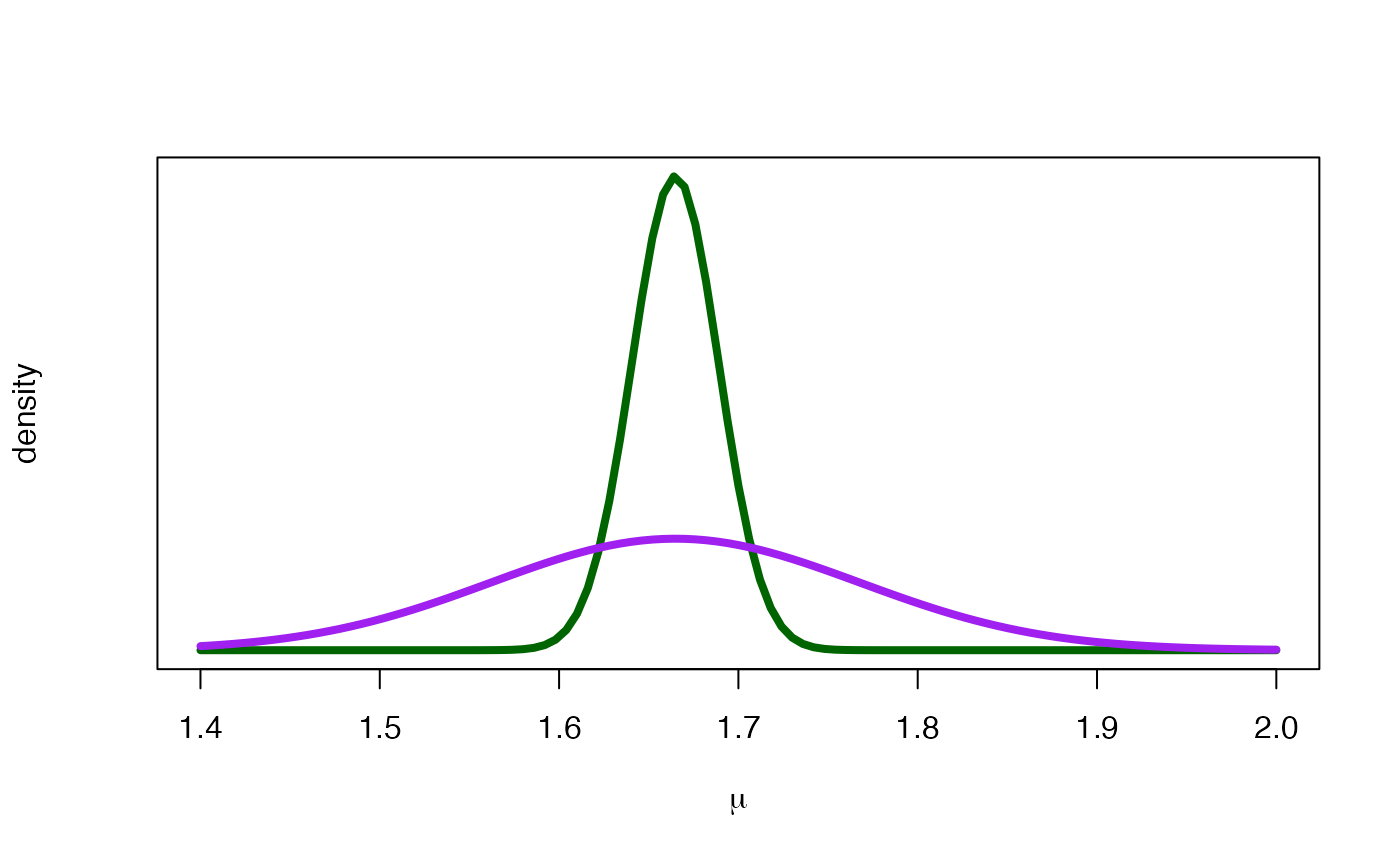
Predictive (purple) and posterior (green) distributions for the mean height.
We can calculate prediction intervals for the height of Aninè. A prediction interval at 95% would be
This indicates that the probability that Aninè’s height is between 1.46 and 1.87 metres is 0.95.
Bayesian inference for the mean height of the women VIBASS participants. The variance of the sampling Normal model is unknown.
If we follow the same scheme as in the previous case where the variance was known, we would have a first section dedicated to the data which would be the same. The sampling model is also approximately Normal but now we will work with a Normal with unknown mean and variance.
The sampling model is approximately Normal
Let the random variable that describes the height of the women in VIBASS. We assume that the distribution of is Normal with unknown mean and unknown standard deviation
whose conditional density function, expectation and variance are:
- ,
A prior distribution for
Our basic quantity of interest is bi-dimensional . We work in a non-informative prior scenario and use the improper reference prior distribution
The likelihood function of
The likelihood is a function of for the data . It is defined as follows
where is the joint density of the ’s given and evaluated in . Since ’s are independent given and , the joint density is the product of the marginal densities. In our case, the graphic of the likelihood function of will be
The posterior distribution of
The posterior distribution of is a bivariant probability distribution whose joint posterior density function can be expressed in terms of the conditional posterior distribution of given and the marginal posterior distribution of as follows
where
is such that , where
The posterior marginal of is
In our case, the more relevant posterior distributions are the marginal ones:
The posterior marginal is such that
The posterior marginal of
We start working with the posterior . The posterior mean and scale of are and m. A 99 credible interval for is and the posterior probabilities that the mean of the height of the women VIBASS is less than are , respectively.
ny <- length(hwomen$height)
ybar <- mean(hwomen$height)
s2 <- sum((hwomen$height - ybar) ** 2) / (ny - 1)
post_mu <- list(
mean = ybar,
scale = sqrt(s2 / ny)
)
post_mu$scale * qt(c(0.005, 0.995), ny - 1) + post_mu$mean
#> [1] 1.616134 1.703866
pt((c(1.50, 1.60, 1.70, 1.80, 1.90) - post_mu$mean) / post_mu$scale, ny - 1)
#> [1] 1.669533e-08 5.718022e-04 9.916131e-01 9.999999e-01 1.000000e+00The graphics of that posterior density is
curve(
dt((x - post_mu$mean) / post_mu$scale, ny - 1) / post_mu$scale,
xlab = expression(paste(mu)), ylab = "density",
xlim = c(1.40, 2), lwd = 4, col = "darkgreen", yaxt = "n"
)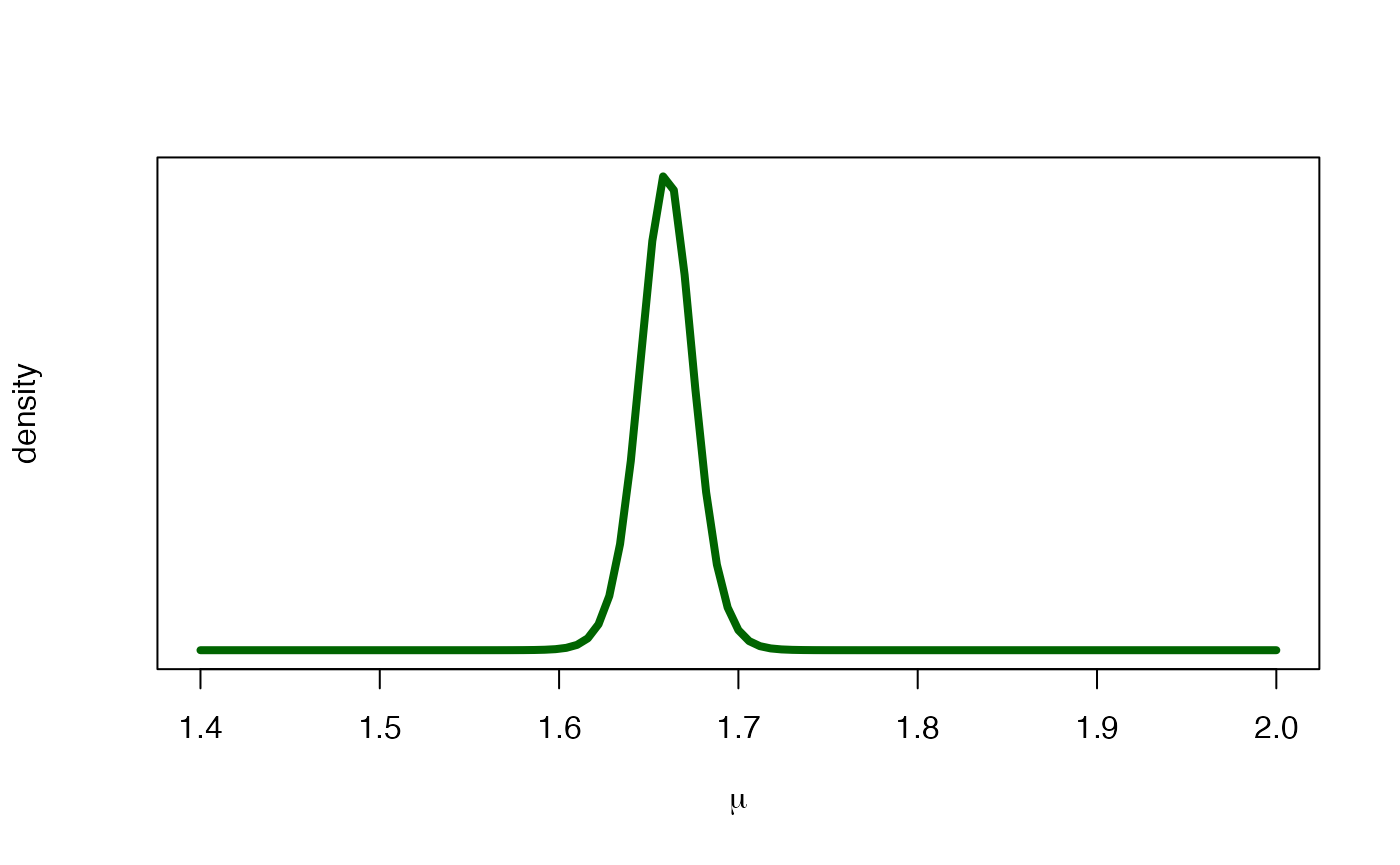
Posterior (green) distribution for the mean height.
We focus now on the variance of the sampling model. Its posterior distribution is such that . This is not the posterior distribution of but a function, , of it. Consequently, we can approximate the posterior distribution for by simulation as follows:
- If is a random sample from then is a random sample from .
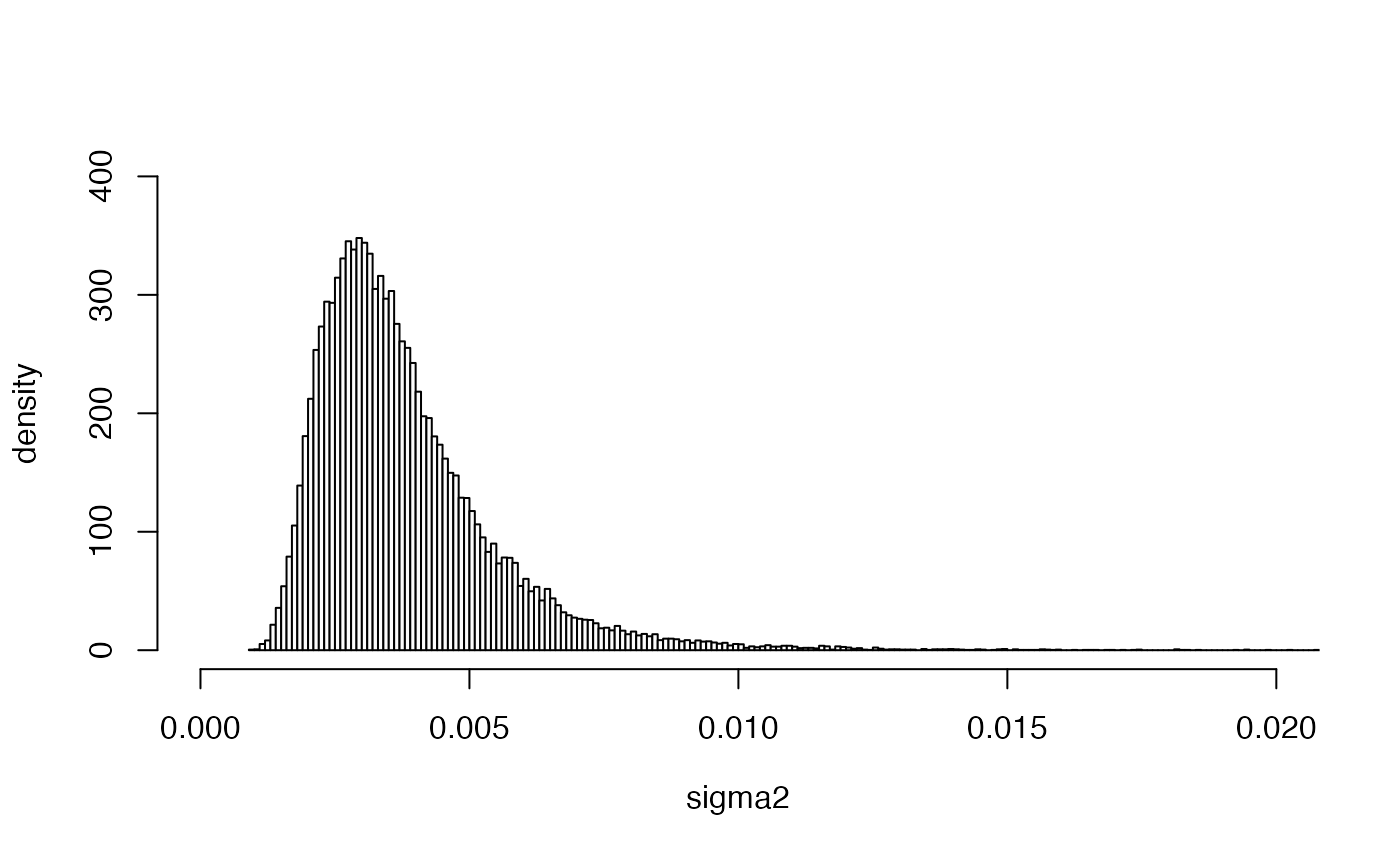
Next we show the approximate graph and some posterior characteristics of the posterior .
y <- seq(0, 40, 0.001)
simuchi <- rchisq(y, ny - 1)
simu.sigma <- 0.045598 / simuchi
hist(
simu.sigma,
breaks = 300, freq = FALSE, col = "gray99",
xlim = c(0, 0.02), ylim = c(0, 400),
main = NULL, ylab = "density", xlab = expression(paste(sigma2))
)
summary(simu.sigma)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.000904 0.002667 0.003413 0.003789 0.004466 0.026238
var(simu.sigma)
#> [1] 2.768883e-06
sqrt(var(simu.sigma))
#> [1] 0.001663996
quantile(simu.sigma, probs = c(0.005,0.995))
#> 0.5% 99.5%
#> 0.001468482 0.010937895We observe that and a % credible interval for is .
Time to individual work
We propose below an individual exercise that pursues to consolidate the basic concepts that we have learned in the previous theoretical session and that we have been practising in this session.
Exercice
We focus now on the height of the VIBASS men participants.
hmen <- data.frame(height = c(1.92, 1.82, 1.69, 1.75, 1.72, 1.71, 1.73, 1.69, 1.70, 1.78, 1.88, 1.82, 1.86, 1.65))-
Construct a Bayesian inferential process for the mean of the height of the VIBASS men participants. Assume a non-informative prior scenario and a sampling model approximately Normal with
Known standard deviation .
Unknown variance.
Compare the mean of the height between men and women. Is it possible to compute the posterior probability associated to ? and to ?