Software for Bayesian Statistical Analysis
So far, simple Bayesian models with conjugate priors have been considered. As explained in previous practicals, when the posterior distribution is not available in closed form, MCMC algorithms such as the Metropolis-Hastings or Gibbs Sampling can be used to obtain samples from it.
In general, posterior distributions are seldom available in closed form and implementing MCMC algorithms for complex models can be technically difficult and very time-consuming.
For this reason, in this Practical we start by looking at a number of
R packages to fit Bayesian statistical models. These
packages will equip us with tools which can be used to deal with more
complex models efficiently, without us having to do a lot of extra
coding ourselves. Fitting Bayesian models in R will then be
much like fitting non-Bayesian models, using model-fitting functions at
the command line, and using standard syntax for model specification.
BayesX
In particular, the following software package will be considered:
BayesX (https://www.uni-goettingen.de/de/bayesx/550513.html)
implements MCMC methods to obtain samples from the joint posterior and
is conveniently accessed from R via the package
R2BayesX.
R2BayesX has a very simple interface to define models
using a formula (in the same way as with glm()
and gam() functions).
R2BayesX can be installed from CRAN.
Other Bayesian Software
Package
MCMCpackin R contains functions such asMCMClogit(),MCMCPoisson()andMCMCprobit()for fitting specific kinds of models.INLA(https://www.r-inla.org/) is based on producing (accurate) approximations to the marginal posterior distributions of the model parameters. Although this can be enough most of the time, making multivariate inference withINLAcan be difficult or impossible. However, in many cases this is not needed andINLAcan fit some classes of models in a fraction of the time it takes with MCMC. It has a very simple interface to define models, although it cannot be installed directly from CRAN - instead you have a specific website where it can be downloaded: https://www.r-inla.org/download-installThe
Stansoftware implements Hamiltonian Monte Carlo and other methods for fit hierarchical Bayesian models. It is available from https://mc-stan.org.Packages
rstanarmandbrmsin R provide a higher-level interface toStanallowing to fit a large class of regression models, with a syntax very similar to classical regression functions in R.A classic MCMC program is
BUGS, (Bayesian Analysis using Gibbs Sampling) described in Lunn et al. (2000): https://www.mrc-bsu.cam.ac.uk/software/bugs-project. BUGS can be used through graphical interfacesWinBUGSandOpenBUGS. Both of these packages can be called from within R using packagesR2WinBUGSandR2OpenBUGS.JAGS, which stands for “just another Gibbs sampler”. Can also be called from R using packager2jags.The
NIMBLEpackage extendsBUGSand implements MCMC and other methods for Bayesian inference. You can get it from https://r-nimble.org, and is best run directly from R.
Bayesian Logistic Regression
Model Formulation
To summarise the model formulation presented in the lecture, given a response variable representing the count of a number of successes from a given number of trials with success probability , we have
assuming the logit link function and with linear predictor .
Example: Fake News
The fake_news data set in the bayesrules
package in R contains information about 150 news articles,
some real news and some fake news.
In this example, we will look at trying to predict whether an article of news is fake or not given three explanatory variables.
We can use the following code to extract the variables we want from the data set:
The response variable type takes values
fake or real, which should be
self-explanatory. The three explanatory variables are:
title_has_excl, whether or not the article contains an excalamation mark (valuesTRUEorFALSE);title_words, the number of words in the title (a positive integer); andnegative, a sentiment rating, recorded on a continuous scale.
In the exercise to follow, we will examine whether the chance of an article being fake news is related to the three covariates here.
Fitting Bayesian Logistic Regression Models
BayesX makes inference via MCMC, via the
R2BayesX package which as noted makes the syntax for model
fitting very similar to that for fitting non-Bayesian models using
glm() in R. If you do not yet have it installed, you can
install it in the usual way from CRAN.
The package must be loaded into R:
library(R2BayesX)
#> Loading required package: BayesXsrc
#> Loading required package: colorspace
#> Loading required package: mgcv
#> Loading required package: nlme
#> This is mgcv 1.9-1. For overview type 'help("mgcv-package")'.The syntax for fitting a Bayesian Logistic Regression Model with one response variable and three explanatory variables will be like so:
model1 <- bayesx(
formula = y ~ x1 + x2 + x3,
data = data.set,
family = "binomial"
)Model Fitting
Note that the variable title_has_excl will need to be
either replaced by or converted to a factor, for example
fakenews$titlehasexcl <- as.factor(fakenews$title_has_excl)Functions summary() and confint() produce a
summary (including parameter estimates etc) and confidence intervals for
the parameters, respectively.
In order to be able to obtain output plots from BayesX,
it seems that we need to create a new version of the response variable
of type logical:
fakenews$typeFAKE <- fakenews$type == "fake"Exercises
-
Perform an exploratory assessment of the fake news data set, in particular looking at the possible relationships between the explanatory variables and the fake/real response variable
typeFAKE. You may wish to use the R functionboxplot()here.Solution
# Is there a link between the fakeness and whether the title has an exclamation mark? table(fakenews$title_has_excl, fakenews$typeFAKE) #> #> FALSE TRUE #> FALSE 88 44 #> TRUE 2 16 # For the quantitative variables, look at boxplots on fake vs real boxplot(fakenews$title_words ~ fakenews$typeFAKE)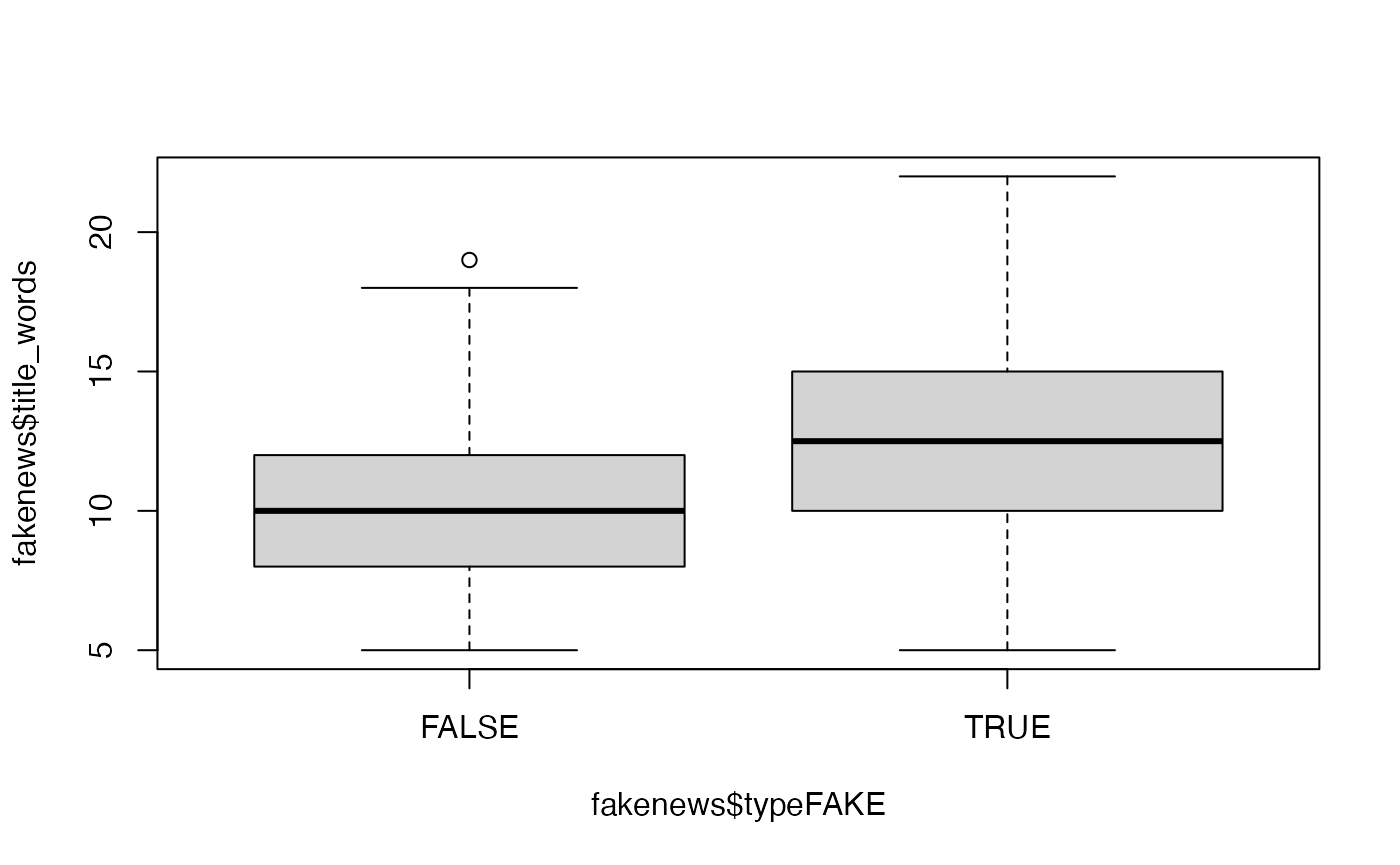
boxplot(fakenews$negative ~ fakenews$typeFAKE)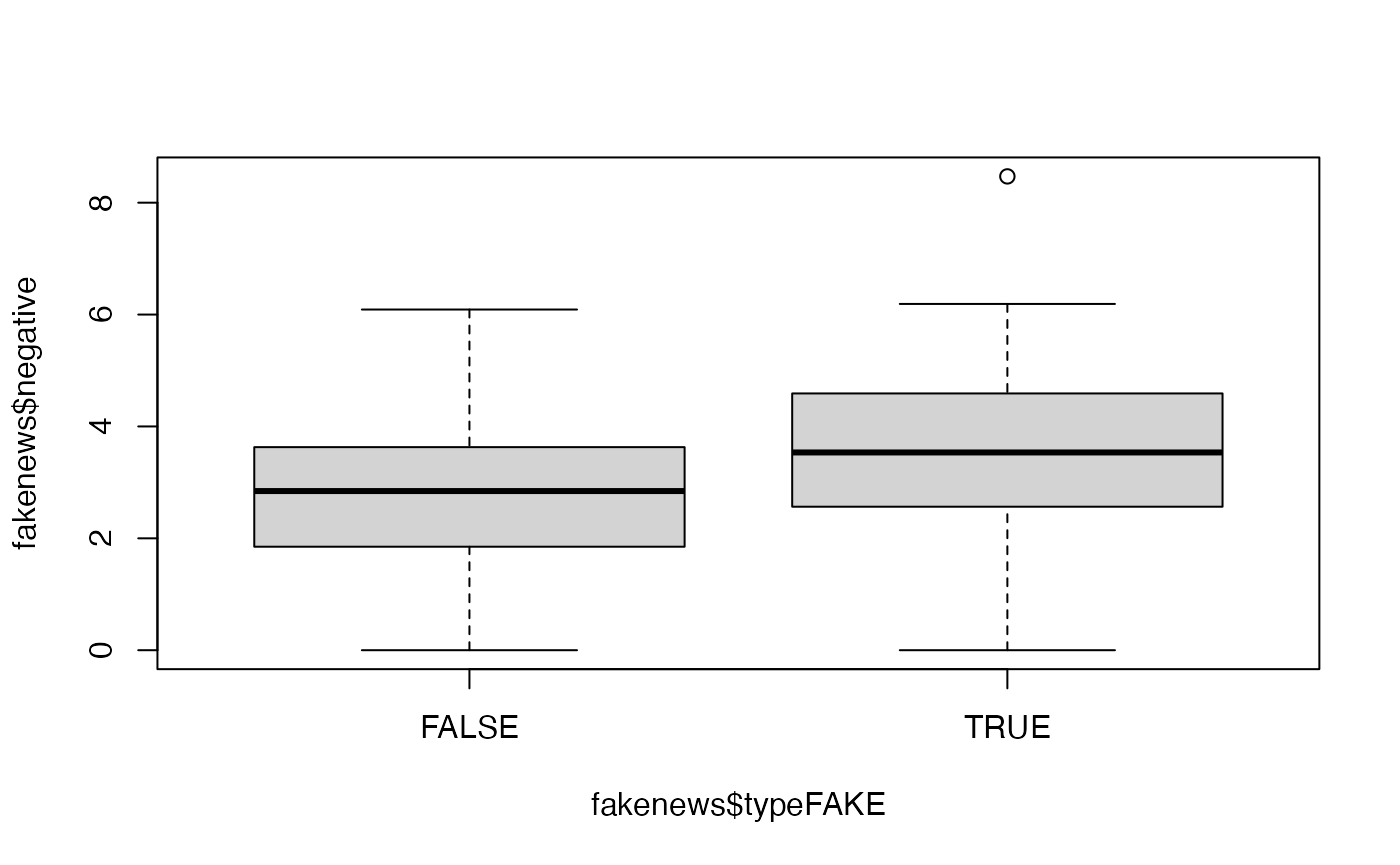
-
Fit a Bayesian model in
BayesXusing the fake newstypeFAKEvariable as response and the others as covariates. Examine the output; does the model fit well, and is there any evidence that any of the explanatory variables are associated with changes in probability of an article being fake or not?Solution
# Produce the BayesX output bayesx.output <- bayesx(formula = typeFAKE ~ titlehasexcl + title_words + negative, data = fakenews, family = "binomial", method = "MCMC", iter = 15000, burnin = 5000) summary(bayesx.output) #> Call: #> bayesx(formula = typeFAKE ~ titlehasexcl + title_words + negative, #> data = fakenews, family = "binomial", method = "MCMC", iter = 15000, #> burnin = 5000) #> #> Fixed effects estimation results: #> #> Parametric coefficients: #> Mean Sd 2.5% 50% 97.5% #> (Intercept) -2.9894 0.7843 -4.5582 -2.9716 -1.3947 #> titlehasexclTRUE 2.7615 0.9268 1.2487 2.6605 5.1330 #> title_words 0.1145 0.0592 -0.0072 0.1139 0.2261 #> negative 0.3242 0.1629 0.0220 0.3186 0.6485 #> #> N = 150 burnin = 5000 method = MCMC family = binomial #> iterations = 15000 step = 10 confint(bayesx.output) #> 2.5% 97.5% #> (Intercept) -4.553338750 -1.3992430 #> titlehasexclTRUE 1.253023500 5.1184442 #> title_words -0.006889553 0.2256098 #> negative 0.023594783 0.6466613 -
Produce plots of the MCMC sample traces and the estimated posterior distributions for the model parameters. Does it seem like convergence has been achieved?
Solution
# Traces can be obtained separately plot(bayesx.output,which = "coef-samples")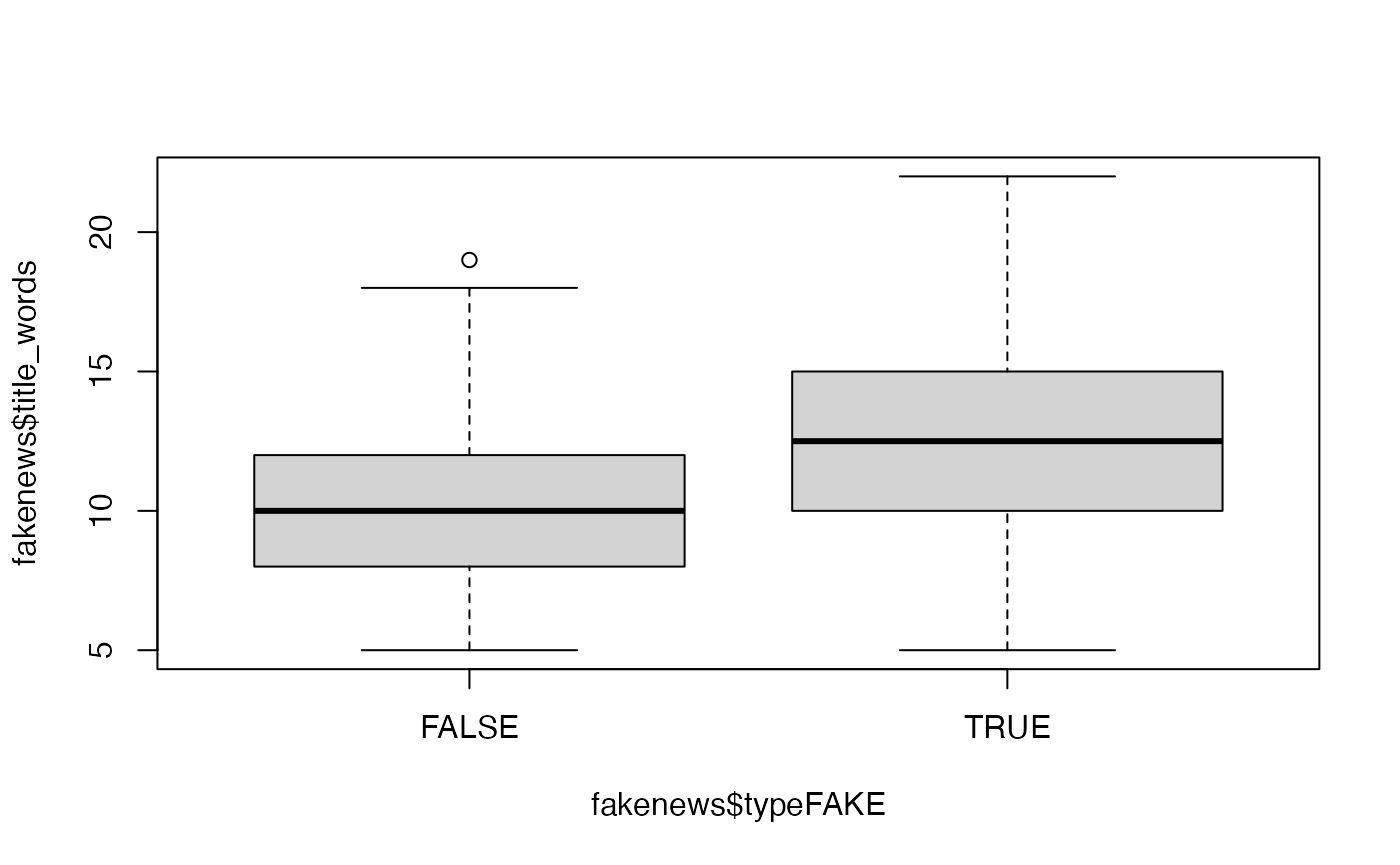
# And the density plots one-by-one oldpar <- par(mfrow = c(2, 2)) plot(density(samples(bayesx.output)[,"titlehasexclTRUE"]),main="Title Has Excl") plot(density(samples(bayesx.output)[,"title_words"]),main="Title Words") plot(density(samples(bayesx.output)[,"negative"]),main="Negative") par(oldpar)
-
Fit a non-Bayesian model using
glm()for comparison. How do the model fits compare?Solution
# Fit model - note similarity with bayesx syntax glm.output <- glm(formula = typeFAKE ~ titlehasexcl + title_words + negative, data = fakenews, family = "binomial") # Summarise output summary(glm.output) #> #> Call: #> glm(formula = typeFAKE ~ titlehasexcl + title_words + negative, #> family = "binomial", data = fakenews) #> #> Coefficients: #> Estimate Std. Error z value Pr(>|z|) #> (Intercept) -2.91516 0.76096 -3.831 0.000128 *** #> titlehasexclTRUE 2.44156 0.79103 3.087 0.002025 ** #> title_words 0.11164 0.05801 1.925 0.054278 . #> negative 0.31527 0.15371 2.051 0.040266 * #> --- #> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 #> #> (Dispersion parameter for binomial family taken to be 1) #> #> Null deviance: 201.90 on 149 degrees of freedom #> Residual deviance: 169.36 on 146 degrees of freedom #> AIC: 177.36 #> #> Number of Fisher Scoring iterations: 4 # Perform ANOVA on each variable in turn drop1(glm.output,test="Chisq") #> Single term deletions #> #> Model: #> typeFAKE ~ titlehasexcl + title_words + negative #> Df Deviance AIC LRT Pr(>Chi) #> <none> 169.36 177.36 #> titlehasexcl 1 183.51 189.51 14.1519 0.0001686 *** #> title_words 1 173.17 179.17 3.8099 0.0509518 . #> negative 1 173.79 179.79 4.4298 0.0353162 * #> --- #> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Bayesian Poisson Regression
Model Formulation
To summarise the model formulation presented in the lecture, given a response variable representing the counts occurring from a process with mean parameter :
assuming the log link function and with linear predictor .
Example: Emergency Room Complaints
For this example we will use the esdcomp data set, which
is available in the faraway package. This data set records
complaints about emergency room doctors. In particular, data was
recorded on 44 doctors working in an emergency service at a hospital to
study the factors affecting the number of complaints received.
The response variable that we will use is complaints, an
integer count of the number of complaints received. It is expected that
the number of complaints will scale by the number of visits (contained
in the visits column), so we are modelling the rate of
complaints per visit - thus we will need to include a new variable
logvisits as an offset.
The three explanatory variables we will use in the analysis are:
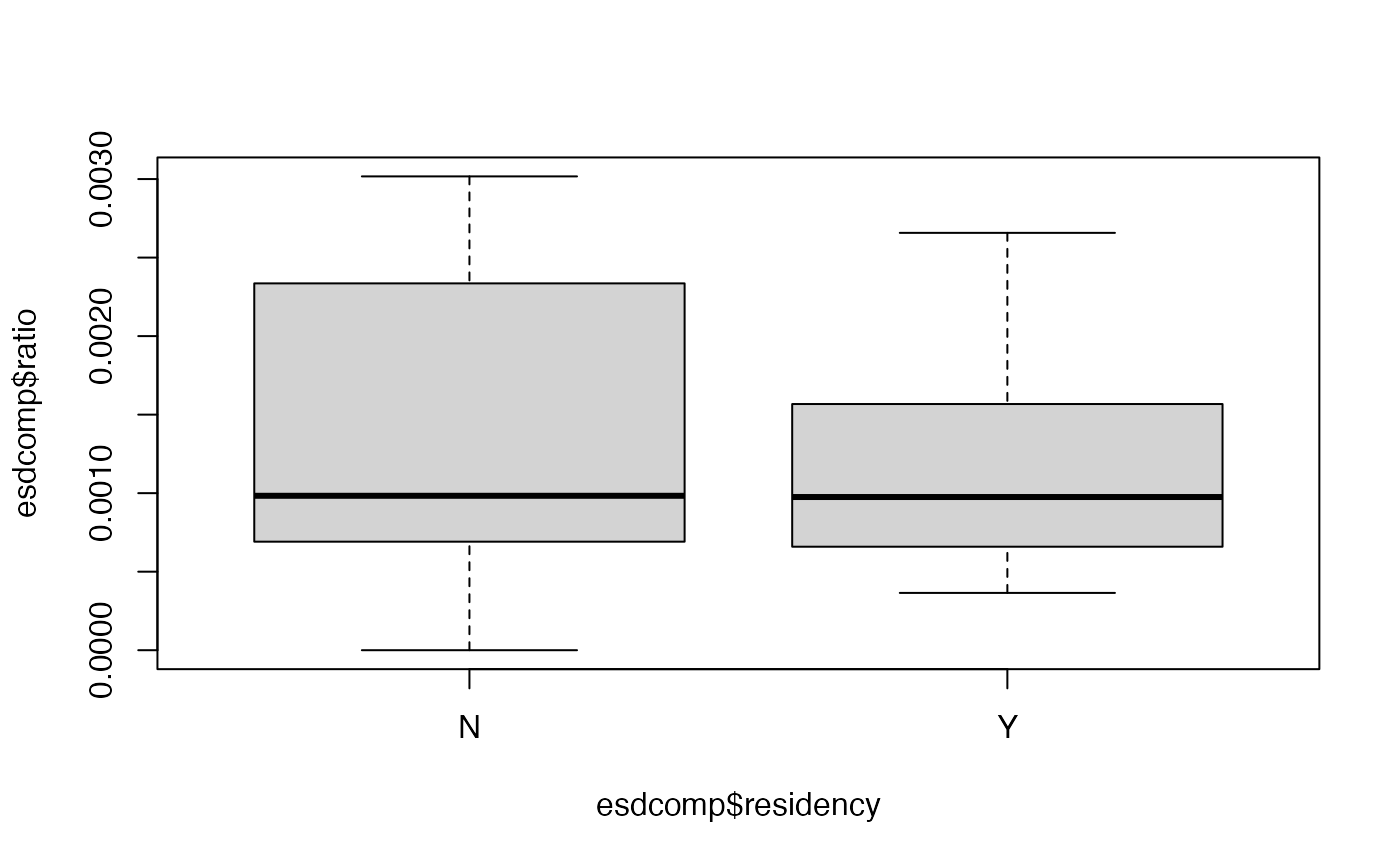
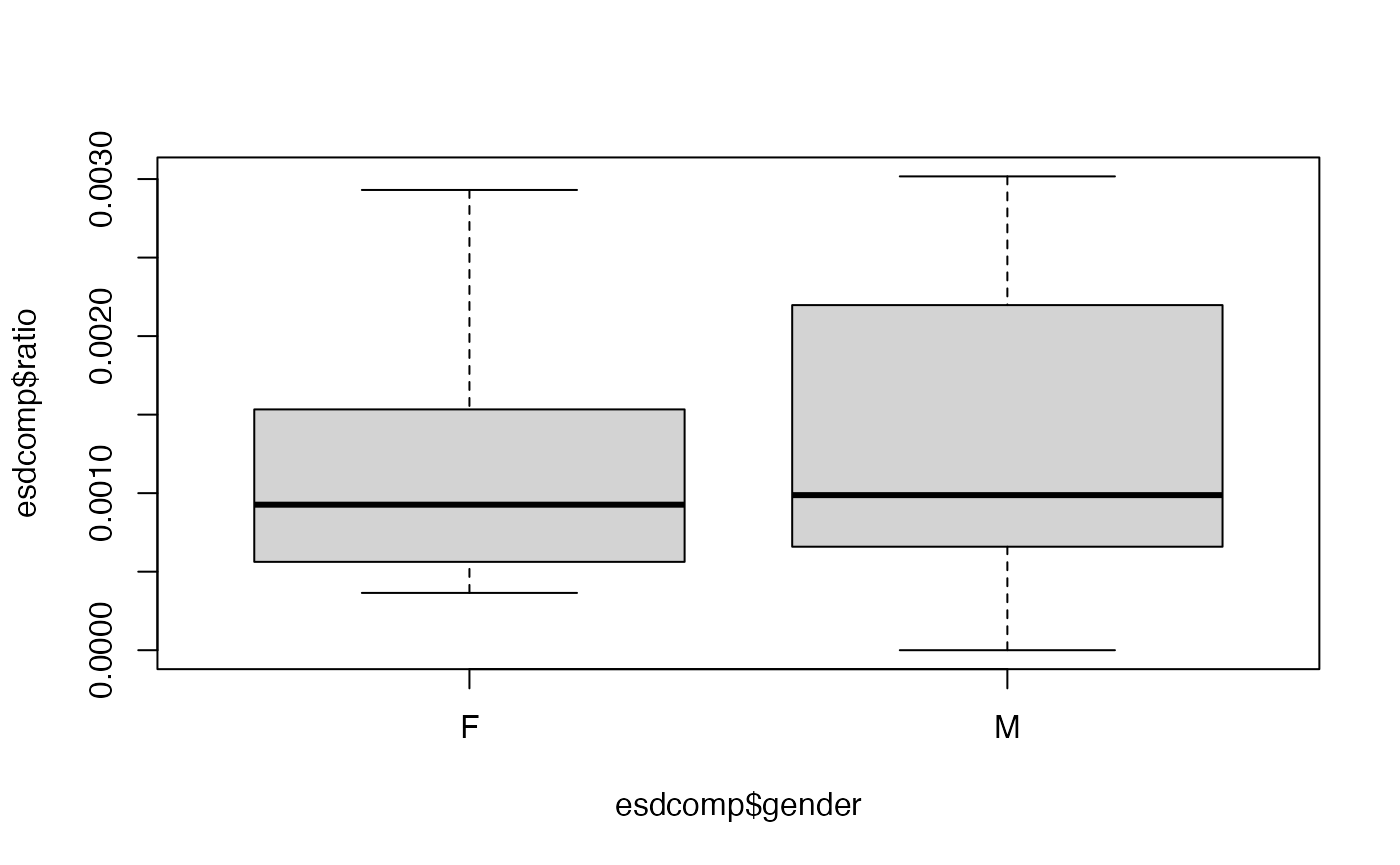
residency, whether or not the doctor is still in residency training (valuesNorY);gender, the gender of the doctor (valuesForM); andrevenue, dollars per hour earned by the doctor, recorded as an integer.
Our simple aim here is to assess whether the seniority, gender or income of the doctor is linked with the rate of complaints against that doctor.
We can use the following code to extract the data we want without having to load the whole package:
esdcomp <- faraway::esdcompFitting Bayesian Poisson Regression Models
Again we can use BayesX to fit this form of Bayesian
generalised linear model.
If not loaded already, the package must be loaded into R:
In BayesX, the syntax for fitting a Bayesian Poisson
Regression Model with one response variable, three explanatory variables
and an offset will be like so:
As noted above we need to include an offset in this analysis; since
for a Poisson GLM we will be using a log link function by default, we
must compute the log of the number of visits and include that in the
data set esdcomp:
esdcomp$logvisits <- log(esdcomp$visits)The offset term in the model is then written
offset(logvisits)
in the call to bayesx().
Exercises
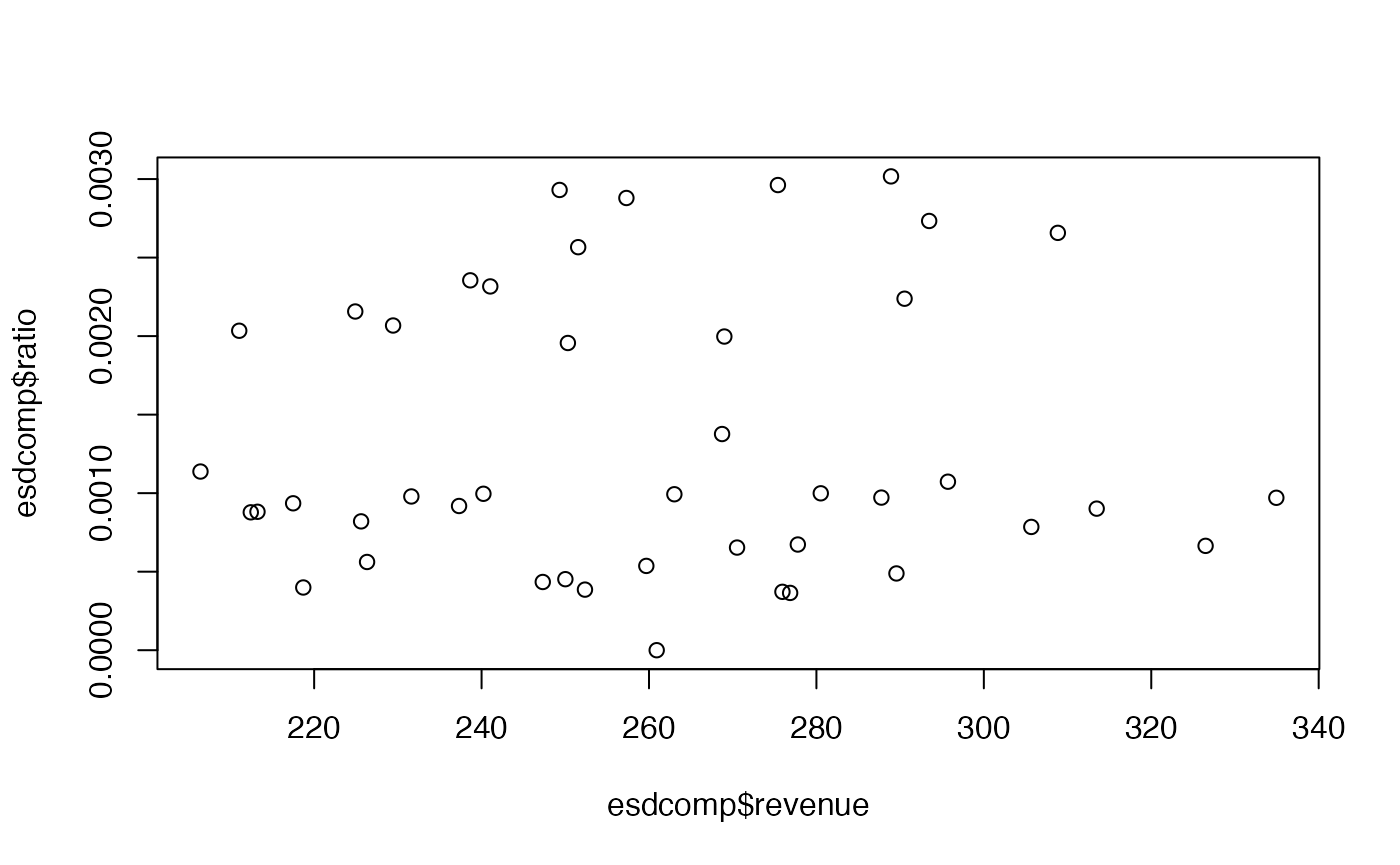
-
Perform an exploratory assessment of the emergency room complaints data set, particularly how the response variable
complaintsvaries with the proposed explanatory variables relative to the number of visits. To do this, create another variable which is the ratio ofcomplaintstovisits. -
Fit a Bayesian model in
BayesXusing thecomplaintsvariable as Poisson response and the others as covariates. Examine the output; does the model fit well, and is there any evidence that any of the explanatory variables are associated with the rate of complaints?Solution
# Fit model - note similarity with glm syntax esdcomp$logvisits <- log(esdcomp$visits) bayesx.output <- bayesx(formula = complaints ~ residency + gender + revenue, offset = logvisits, data = esdcomp, family = "poisson") # Summarise output summary(bayesx.output) #> Call: #> bayesx(formula = complaints ~ residency + gender + revenue, data = esdcomp, #> offset = logvisits, family = "poisson") #> #> Fixed effects estimation results: #> #> Parametric coefficients: #> Mean Sd 2.5% 50% 97.5% #> (Intercept) -7.1678 0.6841 -8.5077 -7.1564 -5.8598 #> residencyY -0.3443 0.1953 -0.7247 -0.3553 0.0458 #> genderM 0.1449 0.2098 -0.2469 0.1447 0.5755 #> revenue 0.0023 0.0028 -0.0029 0.0023 0.0079 #> #> N = 44 burnin = 2000 method = MCMC family = poisson #> iterations = 12000 step = 10 -
Produce plots of the MCMC sample traces and the estimated posterior distributions for the model parameters. Does it seem like convergence has been achieved?
Solution
# An overall plot of sample traces and density estimates # plot(samples(bayesx.output)) # Traces can be obtained separately plot(bayesx.output,which = "coef-samples")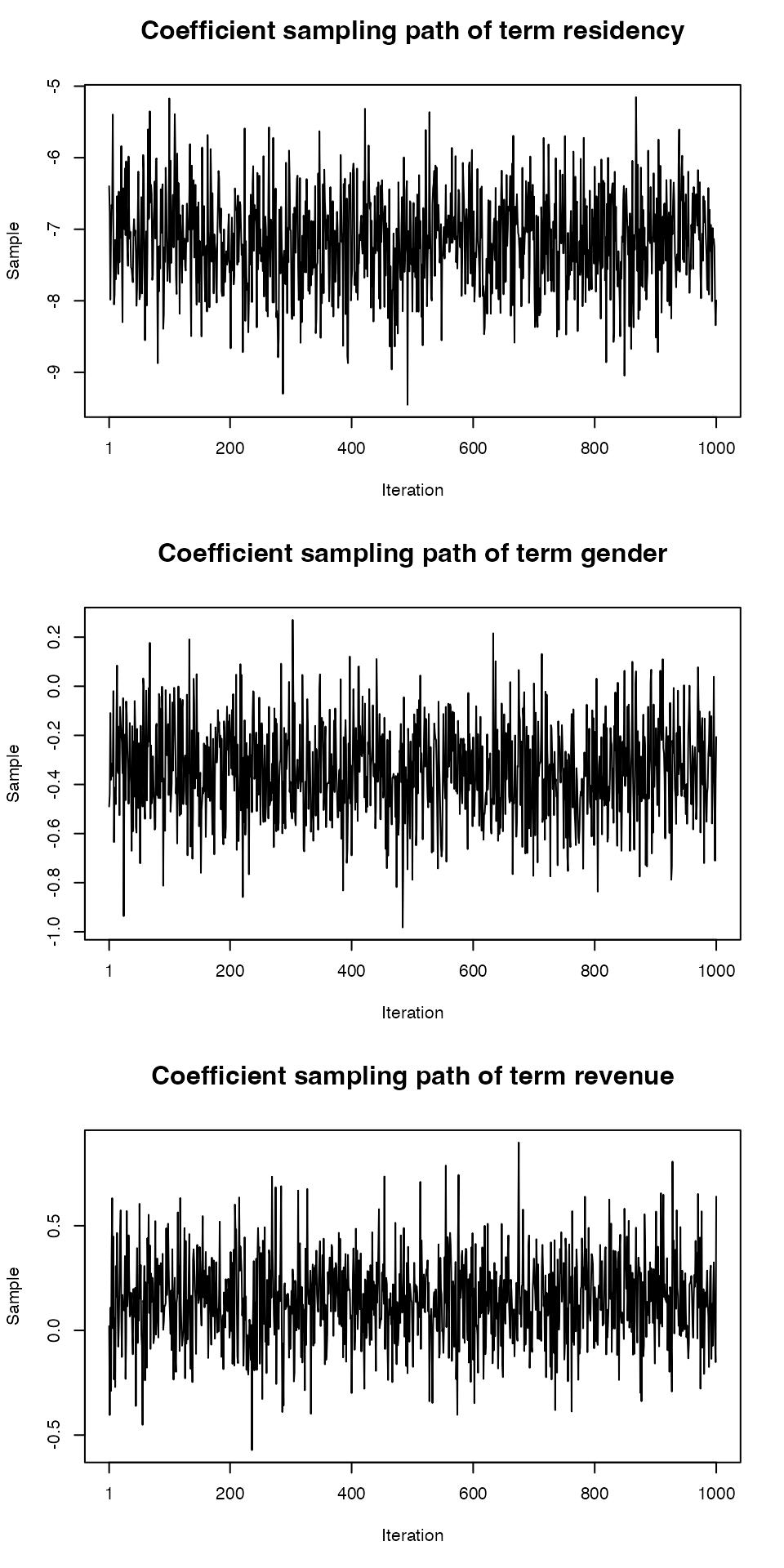
# And the density plots one-by-one oldpar <- par(mfrow = c(2, 2)) plot(density(samples(bayesx.output)[, "residencyY"]), main = "Residency") plot(density(samples(bayesx.output)[, "genderM"]), main = "Gender") plot(density(samples(bayesx.output)[, "revenue"]), main = "Revenue") par(oldpar)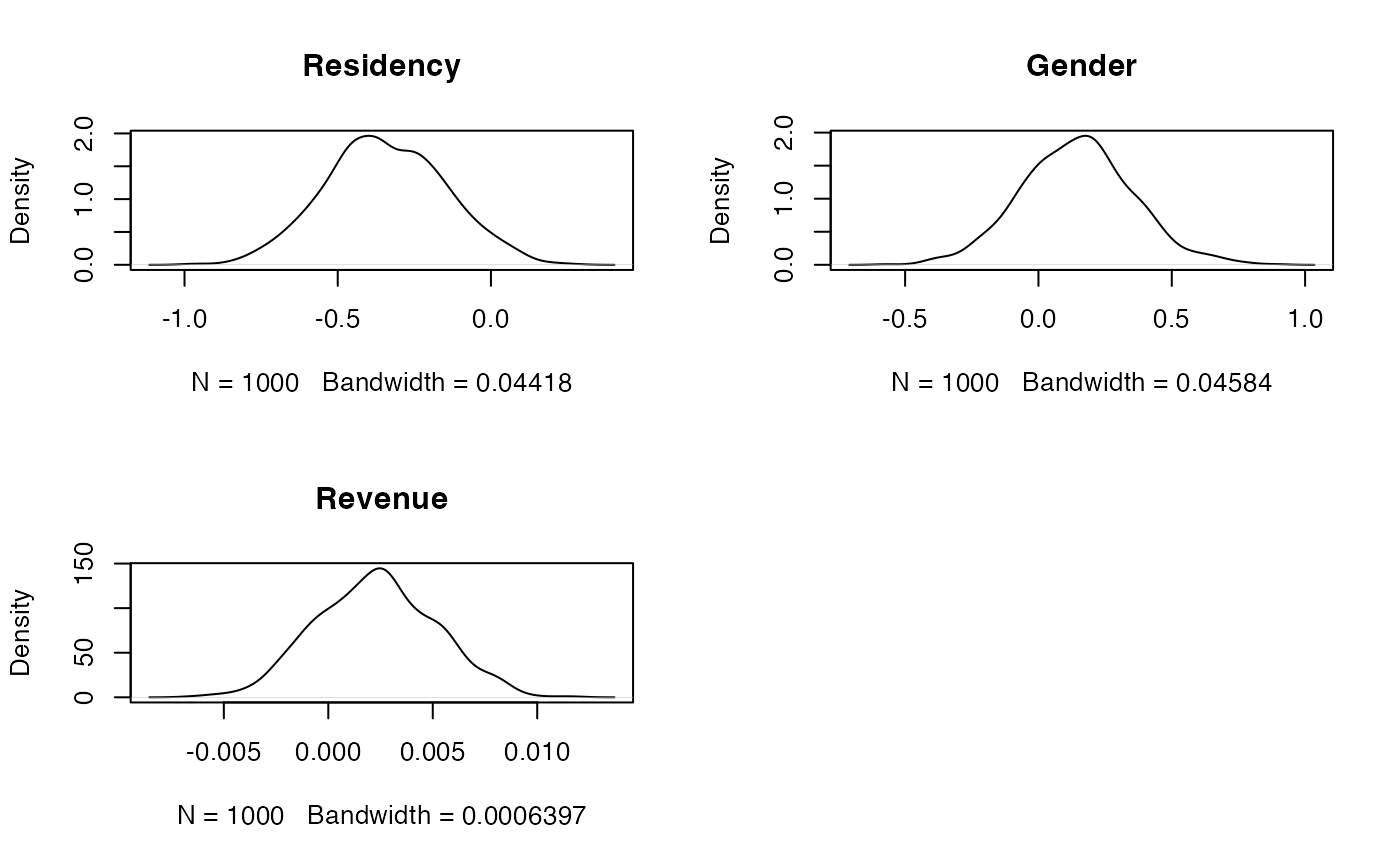
-
Fit a non-Bayesian model using
glm()for comparison. How do the model fits compare?Solution
# Fit model - note similarity with bayesx syntax esdcomp$log.visits <- log(esdcomp$visits) glm.output <- glm(formula = complaints ~ residency + gender + revenue, offset = logvisits, data = esdcomp, family = "poisson") # Summarise output summary(glm.output) #> #> Call: #> glm(formula = complaints ~ residency + gender + revenue, family = "poisson", #> data = esdcomp, offset = logvisits) #> #> Coefficients: #> Estimate Std. Error z value Pr(>|z|) #> (Intercept) -7.157087 0.688148 -10.401 <2e-16 *** #> residencyY -0.350610 0.191077 -1.835 0.0665 . #> genderM 0.128995 0.214323 0.602 0.5473 #> revenue 0.002362 0.002798 0.844 0.3986 #> --- #> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 #> #> (Dispersion parameter for poisson family taken to be 1) #> #> Null deviance: 63.435 on 43 degrees of freedom #> Residual deviance: 58.698 on 40 degrees of freedom #> AIC: 189.48 #> #> Number of Fisher Scoring iterations: 5 # Perform ANOVA on each variable in turn drop1(glm.output, test = "Chisq") #> Single term deletions #> #> Model: #> complaints ~ residency + gender + revenue #> Df Deviance AIC LRT Pr(>Chi) #> <none> 58.698 189.48 #> residency 1 62.128 190.91 3.4303 0.06401 . #> gender 1 59.067 187.85 0.3689 0.54361 #> revenue 1 59.407 188.19 0.7093 0.39969 #> --- #> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1